Large Language Models Explained: The Technology Behind ChatGPT
Estimated read time: 14 minutes What every business leader needs to understand about the most transformative technology since the internet.What Is a Large Language Model?
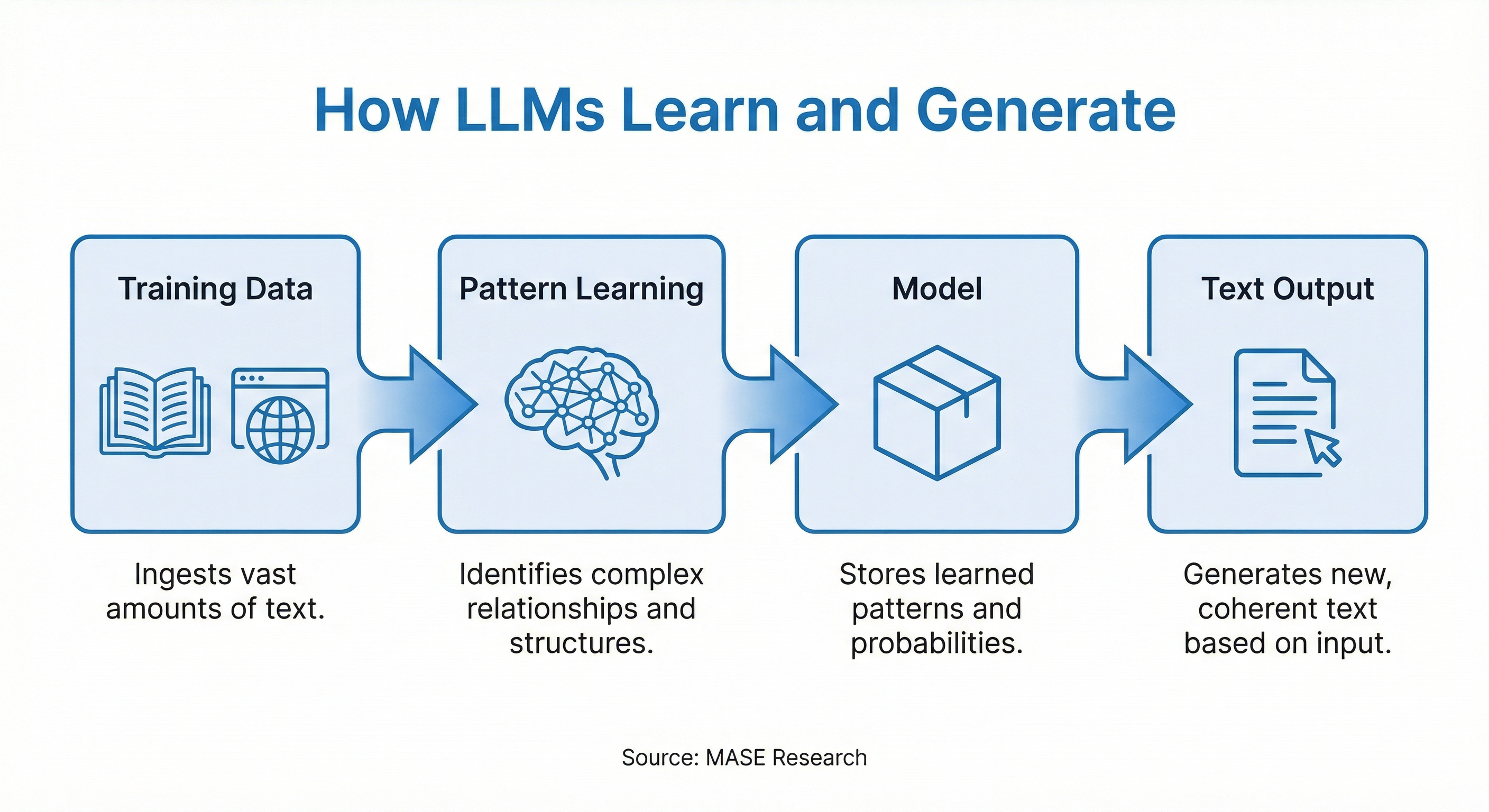
At its core, a large language model is a prediction machine. Specifically, it predicts the next word in a sequence.
That's it. That's the fundamental operation. Given the text "The capital of France is," the model predicts that "Paris" should come next. Given "Dear Mr. Johnson, Thank you for your email regarding," it predicts words like "your," "the," or "our" as likely continuations.
This sounds almost disappointingly simple. How does next-word prediction lead to a system that can write poetry, analyze legal contracts, debug code, and hold nuanced conversations?
The answer lies in scale—and in what happens when you push next-word prediction to its mathematical extremes.
To predict the next word accurately, a model must develop internal representations of how language works. To correctly continue "The Eiffel Tower is located in the city of," the model must implicitly understand that the Eiffel Tower is a structure, that structures have locations, that Paris is a city, and that the Eiffel Tower is specifically in Paris. The prediction task forces the model to build a rich internal model of the world—not because anyone programmed it to, but because that knowledge improves its predictions.
"The shocking discovery of modern AI is that prediction, at sufficient scale, becomes a form of understanding."
This emergent understanding is what separates modern LLMs from the autocomplete on your phone. Your phone's autocomplete learns simple patterns: you often type "running" after "I'm." But it doesn't understand what running is, or why you might be doing it, or how to discuss the philosophy of exercise.
Large language models, trained on hundreds of billions of words, develop something qualitatively different. They learn grammar and syntax, yes. But they also learn facts about the world, logical relationships between concepts, common reasoning patterns, literary styles, emotional nuances, and countless other aspects of human knowledge—all as byproducts of learning to predict words more accurately.
How Scale Creates Capability
The "large" in large language model refers primarily to the number of parameters—the adjustable numerical values that define how the model processes information. Think of parameters as the model's internal configuration: billions of tiny dials that, collectively, encode everything the model has learned.
GPT-3, released in 2020, contained 175 billion parameters. GPT-4, released in 2023, is rumored to contain over one trillion parameters (OpenAI has not confirmed exact numbers). Claude 3, Anthropic's flagship model, operates at similar scales. Google's Gemini Ultra represents a comparable investment in model size.
To train these models, companies feed them staggering amounts of text. GPT-4 was reportedly trained on approximately 13 trillion tokens—roughly equivalent to 10 million books. The training data includes websites, books, scientific papers, code repositories, and countless other text sources.
What happens when you scale up? Researchers have discovered something remarkable: capabilities emerge suddenly and unpredictably. A model that can't perform arithmetic at 10 billion parameters might suddenly develop arithmetic ability at 100 billion parameters. A model that produces garbled reasoning at one scale might produce coherent, step-by-step analysis at the next scale up.
These "emergent capabilities" caught researchers by surprise. OpenAI, Google DeepMind, and Anthropic have all documented instances where scaling led to capabilities that weren't explicitly trained and weren't predicted by performance at smaller scales.
The implication is profound: we don't fully understand why these models work as well as they do. We designed the training process, but the capabilities that emerged were not specifically programmed. This is simultaneously exciting and humbling—we've created something powerful that we don't entirely understand.
The Training Process: A Simple Explanation
Large language models are developed in three main phases, each building on the last.
Phase 1: Pre-Training
Pre-training is where the model learns to predict words. The process works like this:
This process takes months on specialized hardware that costs tens of millions of dollars. But the result is a model with broad knowledge of language, facts, reasoning patterns, and even cultural context—all learned through the deceptively simple task of predicting what word comes next.
Phase 2: Fine-Tuning
A pre-trained model is knowledgeable but not particularly useful. It will continue any text you give it, but it doesn't understand what you actually want. Ask it a question, and it might generate another question, or an advertisement, or continue in a completely irrelevant direction.
Fine-tuning aligns the model with human intentions. Researchers create datasets of ideal responses: "Here's a question a user might ask, and here's how a helpful assistant should respond." The model is then trained on these examples, learning to produce the kinds of responses humans find useful.
This phase is far cheaper than pre-training—hours rather than months—but it's crucial for transforming a word-predictor into an assistant.
Phase 3: Reinforcement Learning from Human Feedback (RLHF)
The final phase refines the model's judgment through human feedback. The process works roughly like this:
This technique, pioneered by OpenAI and refined by Anthropic and others, is what makes modern chatbots feel conversational rather than mechanical. The model learns not just what's accurate, but what's helpful, clear, and appropriate.
Anthropic has extended this approach with their "Constitutional AI" method, where models are trained to follow ethical principles and explain their reasoning—an attempt to make AI systems that are not just capable but aligned with human values.
"RLHF is how we teach machines what humans actually want—not just what they literally say."
Why LLMs Can Write, Analyze, and Converse
Given what we've discussed, the capabilities of LLMs become less mysterious.
Writing: The models have learned, through exposure to billions of examples, what good writing looks like in countless contexts. They've absorbed the patterns of business memos, academic papers, marketing copy, poetry, and dialogue. When asked to write in a specific style, they draw on this vast implicit knowledge. Analysis: To predict text accurately, models must understand logical relationships. They've seen millions of examples of arguments being constructed, evidence being evaluated, and conclusions being drawn. They can reproduce these patterns because they've learned them deeply. Conversation: The models have been exposed to dialogue of every kind—customer service interactions, interviews, debates, casual conversations. Combined with RLHF training that rewards helpful and coherent responses, they've learned to maintain context, address questions, and engage in back-and-forth exchange. Code: Programming languages are structured text with precise rules. Models trained on millions of code examples have learned syntax, common patterns, and even the logic of debugging—all through the same next-token prediction that powers their language abilities.The key insight is that these aren't separate capabilities bolted onto a language model. They're all manifestations of the same underlying mechanism: sophisticated pattern matching and generation, learned from astronomical quantities of human-generated text.
How LLMs Differ from Other AI
It's easy to lump all AI together, but large language models represent a distinct approach with unique characteristics.
Traditional Machine Learning typically trains specialized models for narrow tasks: this model detects spam, that model predicts customer churn, another classifies images. Each model is purpose-built and trained on task-specific data. LLMs, by contrast, are generalists—one model can write essays, translate languages, analyze sentiment, and answer factual questions. Expert Systems from earlier AI eras used hand-coded rules created by human experts. They were brittle and required enormous manual effort. LLMs learn their rules automatically from data, making them more flexible and far less labor-intensive to develop. Robotic Process Automation (RPA) follows exact scripted workflows. It can click this button, copy that field, paste it there. LLMs can handle ambiguity and variation—if a form field is in a slightly different location, an LLM can figure it out. But unlike RPA, LLMs may make mistakes in straightforward tasks. Computer Vision and Speech Recognition models process images and audio. LLMs process text. Modern multimodal models like GPT-4 Vision and Gemini combine these capabilities, analyzing images and text together, representing a convergence of previously separate AI domains.The distinctive power of LLMs lies in their generality. You don't need a different model for each task. One model, through careful prompting, can serve dozens of functions. This generality also means they're less specialized—a dedicated sentiment analysis model might outperform an LLM on that specific task. But the flexibility often outweighs the marginal performance loss.
What LLMs Excel At—and Where They Fail
Understanding where LLMs shine and where they stumble is essential for practical deployment.
Genuine Strengths
First drafts and ideation. LLMs excel at generating starting points. First draft of a memo, brainstorming session, initial marketing copy—anywhere you need volume and variety to then refine, LLMs deliver. Translation and transformation. Converting text from one format to another: summarizing long documents, translating between languages, converting bullet points to prose, reformatting data. These transformation tasks play to the model's core strengths. Explanation and teaching. When you need complex concepts explained at different levels—"explain quantum computing to a 12-year-old" versus "explain it to a physics PhD student"—LLMs can flexibly adjust their communication style. Code assistance. For writing boilerplate code, explaining existing code, suggesting debugging approaches, and automating routine programming tasks, LLMs have proven genuinely valuable. Pattern recognition in text. Identifying themes across documents, extracting structured information from unstructured text, recognizing sentiment and intent—tasks that require understanding language at scale.Fundamental Weaknesses
Mathematical reasoning. Despite appearing to perform calculations, LLMs frequently make arithmetic errors. They don't compute; they pattern-match. For anything requiring precise calculation, external tools are essential. Factual accuracy. LLMs "hallucinate"—they generate confident-sounding statements that are simply false. They have no reliable mechanism for distinguishing what they know from what they're fabricating. This is perhaps their most dangerous failure mode. Real-time information. Models are trained on historical data and have no knowledge of events after their training cutoff. They cannot check current stock prices, today's news, or whether a website is currently online."The most dangerous aspect of LLMs isn't what they can't do—it's their tendency to confidently do things wrong."Complex multi-step reasoning. While LLMs can follow arguments and reproduce reasoning patterns, they struggle with genuinely novel logical challenges that require many interdependent steps. Consistency across long contexts. Despite impressive context windows (GPT-4 can process over 100,000 tokens), models often lose track of information mentioned earlier in long documents or conversations.
The Stochastic Parrot Debate
In 2021, researchers Emily Bender, Timnit Gebru, and colleagues published a paper describing LLMs as "stochastic parrots"—systems that recombine patterns from their training data without genuine understanding. The term sparked fierce debate.
The skeptic's position: LLMs are sophisticated autocomplete. They've memorized vast quantities of text and learned to remix it convincingly. But there's "nobody home"—no understanding, no reasoning, no meaning. The impressive outputs are a kind of statistical ventriloquism.
The believer's position: Something significant is happening inside these models. They generalize beyond their training data, solve novel problems, and demonstrate capabilities that weren't explicitly taught. Even if the mechanism is different from human cognition, the functional capabilities are real.
The honest answer: we don't fully know. There's genuine disagreement among experts about whether LLMs represent a meaningful step toward artificial general intelligence or a sophisticated dead end. What we can say is:
For business leaders, the philosophical question matters less than the practical one: what can these systems actually do for you, and where do they break down? The answer to that question is increasingly clear, even as the deeper questions about machine understanding remain unresolved.
Implications for Business Leaders
Understanding LLM fundamentals leads to several strategic implications:
1. The Commoditization of Text Work
Any task that primarily involves transforming, generating, or analyzing text is now subject to AI automation. This doesn't mean humans become unnecessary—it means the premium shifts to judgment, creativity, and quality control rather than volume production. The writer who can edit LLM output into polished prose is more valuable than ever; the writer who competes with LLMs on first-draft speed is in trouble.
2. The Verification Problem
Because LLMs hallucinate, any workflow involving them must include verification. This has organizational implications: you need people or systems that can check LLM outputs. For factual claims, this might mean automatic cross-referencing. For code, it means robust testing. For analysis, it means human review. Building these verification layers is essential for safe deployment.
3. Prompt Engineering as a Core Skill
The same model can be extraordinarily useful or nearly useless depending on how you prompt it. Developing organizational capability in prompt engineering—knowing how to elicit the best outputs—is becoming a genuine competitive advantage. This isn't about tricks; it's about clearly communicating context, constraints, and expectations.
4. The Speed of Capability Development
LLM capabilities are improving rapidly. What's impossible today may be routine in eighteen months. This argues for continuous experimentation and against over-investing in narrow use cases that might be superseded. Build flexible architectures; don't hard-code around current limitations.
5. The Importance of Data Moats
LLMs are trained on public data. Your proprietary data—customer interactions, internal documents, specialized expertise—represents a genuine competitive advantage. Organizations that effectively integrate their unique data with LLM capabilities will outperform those that simply use off-the-shelf models.
Key Takeaways
1. LLMs are prediction engines. At their core, they predict the next word in a sequence. The remarkable capabilities that emerge are byproducts of learning to predict accurately across billions of examples. 2. Scale creates qualitative change. Something unexpected happens when you train models on trillions of tokens with billions of parameters: capabilities emerge that weren't explicitly programmed and weren't present at smaller scales. 3. Training happens in three phases. Pre-training teaches language and knowledge. Fine-tuning teaches the model to be helpful. RLHF aligns the model with human preferences and values. 4. LLMs excel at transformation and generation. They're exceptional at first drafts, translation between formats, explanation, and code assistance. They struggle with math, factual accuracy, and complex reasoning. 5. Hallucination is a fundamental limitation. LLMs cannot reliably distinguish between what they know and what they're fabricating. Any serious deployment must include verification. 6. The philosophical questions are unresolved. Whether LLMs "understand" or merely mimic remains debated. For practical purposes, focus on what they can reliably do. 7. Organizational capabilities matter more than model access. Everyone has access to similar models. Competitive advantage comes from integration, verification, prompt engineering, and effective use of proprietary data.Further Reading
- OpenAI. "GPT-4 Technical Report." arXiv, 2023.
- Anthropic. "Constitutional AI: Harmlessness from AI Feedback." 2022.
- Google DeepMind. "Gemini: A Family of Highly Capable Multimodal Models." 2023.
- Bender, Emily M., et al. "On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?" FAccT, 2021.
- Wei, Jason, et al. "Emergent Abilities of Large Language Models." Transactions on Machine Learning Research, 2022.
This article is part of the MASE Learn Fundamentals track. For the complete curriculum on AI literacy for business leaders, visit MASE Learn.